
Serverless Computing I
Serverless computing is changing the way of computation in the cloud and even in the network edges. Companies are spending time and money to maintain their servers and related software in order to make their business application up and running for their users. Traditional server-based computation slows down companies to go to the market which may lead to negative cash flow for their business. In this article, I’m going to describe serverless computing and compare some serverless platforms and toolkits provided by different companies and open source projects.
Serverless Computation
Traditional Server-based computation, which also called 3-tier architecture, includes three-layer architecture:
-
Presentation Layer where a UI is provided for the user.
-
Application Layer which runs the logic/program.
-
Database Layer which runs the database server
The following figure represents the traditional Server-based computation. 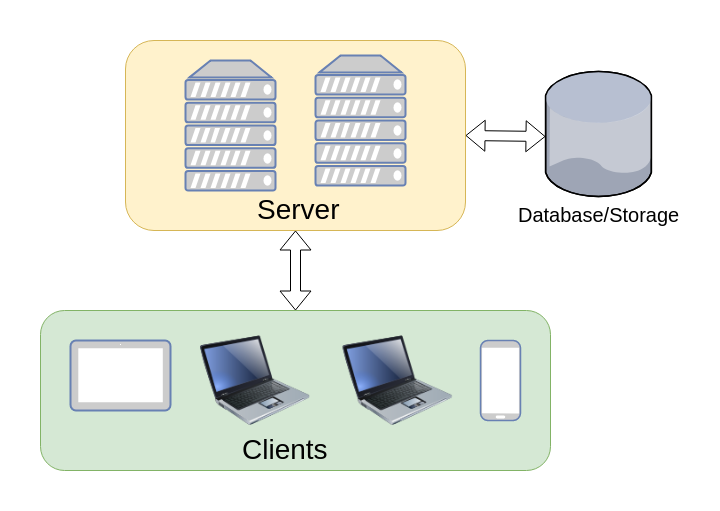
This architecture leads to some disadvantages or extra costs for companies which some of them are:
-
Create or set up a server
-
Install OS and necessary software
-
Manage software/hardware
-
etc
Also, the application/architecture should be highly available and has fault tolerant, load balancing capability, scalability, etc. These disadvantages and requirements lead to the creation of a new concept which is Serverless. Serverless most often refers to serverless applications which are ones that don’t require you to provision or manage any servers [1].
Thus, companies can more focus on their products instead of having responsibilities like Control Access, OS Patching, Scaling and, etc. It worth to mention that Serverless doesn’t mean that there is no server involved, it means that companies don’t need to have a server to manage. Generally, service or platform will be considered as a serverless which has the following capabilities:
-
No server management
-
No OS and Softwares to take care of
-
Flexible scaling
-
Application has built-in high availability and fault tolerance
-
No idle capacity/Costs
-
etc
With this approach companies can focus on the business/logic without having worry about the servers. It means faster time to market. Serverless computation require some layers of infrastructure which are basically cloud service models which are shown in Figure 2. 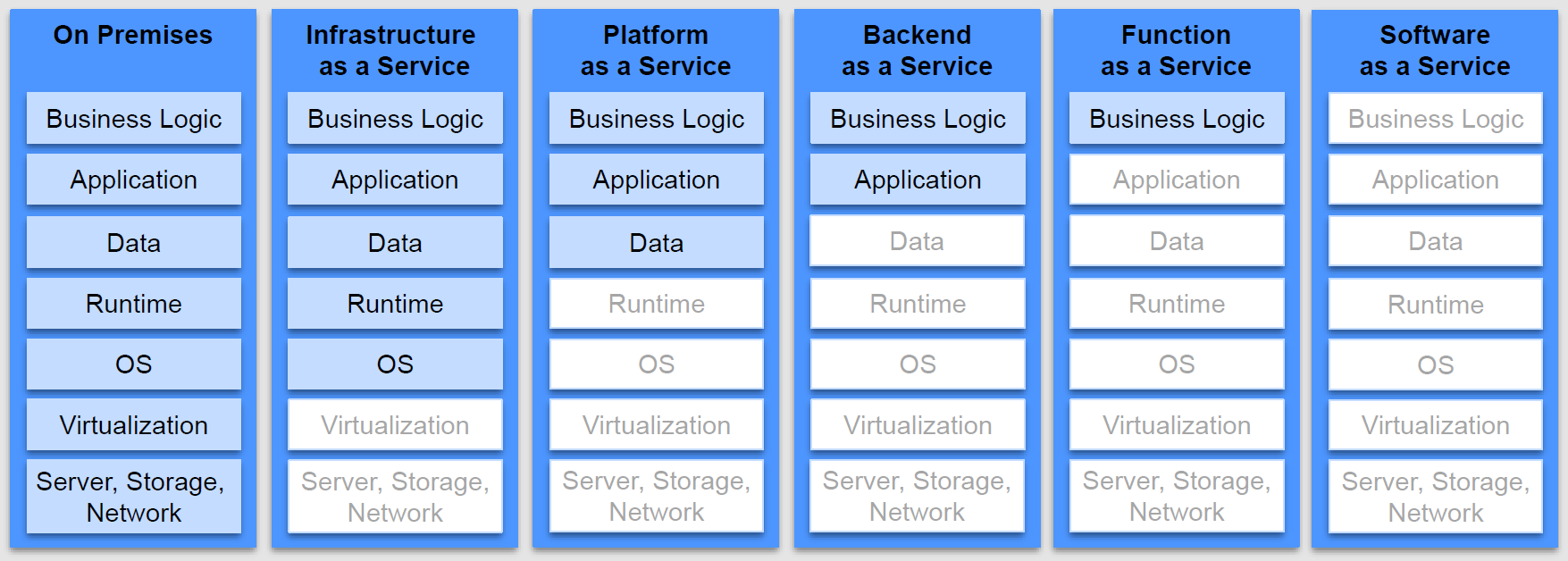
These models, which also lead to the existence of serverless computation, are as following:
-
Platform as a Service (PaaS) is a cloud computing model which third party provider delivers hardware and software tools which are needed for development [3]. Like AWS Elastic Beanstalk, Windows Azure, Heroku, Force.com, Google App Engine, Apache Stratos, OpenShift.
-
Unlike Infrastructure as a Service(IaaS) which provider supplies the basic compute, storage, networking infrastructure along with the hypervisor. Users must then create virtual machines, install operating systems, support applications and data, and handle all of the configuration and management associated with those tasks [3]. Examples of IaaS are DigitalOcean, Linode, Rackspace, Amazon Web Services (AWS), Cisco Metapod, Microsoft Azure, Google Compute Engine (GCE).
Serverless computing is a cloud-computing execution model in which the cloud provider dynamically manages the allocation of machine resources[4]. For instance, if a large number of users want to trigger a lambda function on server side simultaneously, then the cloud provider takes care of scaling and availability of lambda function. Serverless applications use two important services which are shown in Figure 3 and defined as follow:
-
Function as a Service (FaaS) provides a platform that allows customers to develop, run, and manage application functionalities without the complexity of building and maintaining the infrastructure typically associated with developing and launching an app [5]. Serverless computation will lay in this service.
-
Backend as a Service (BaaS) is microservice in the cloud that can run independently and provides user services like user management and authentication, push notification, etc. These services will expose APIs so mobile or web applications have access to them.
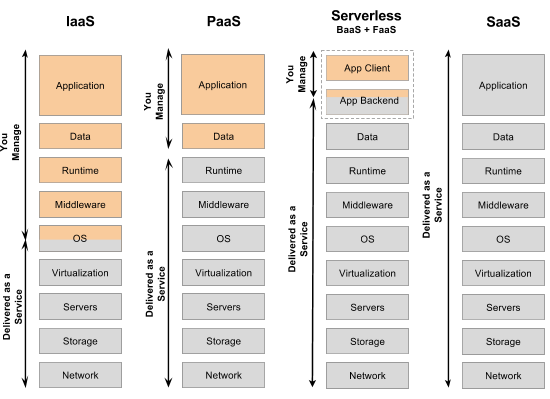
Fig. 3: Cloud Infrastructure with BaaS and FaaS [6]
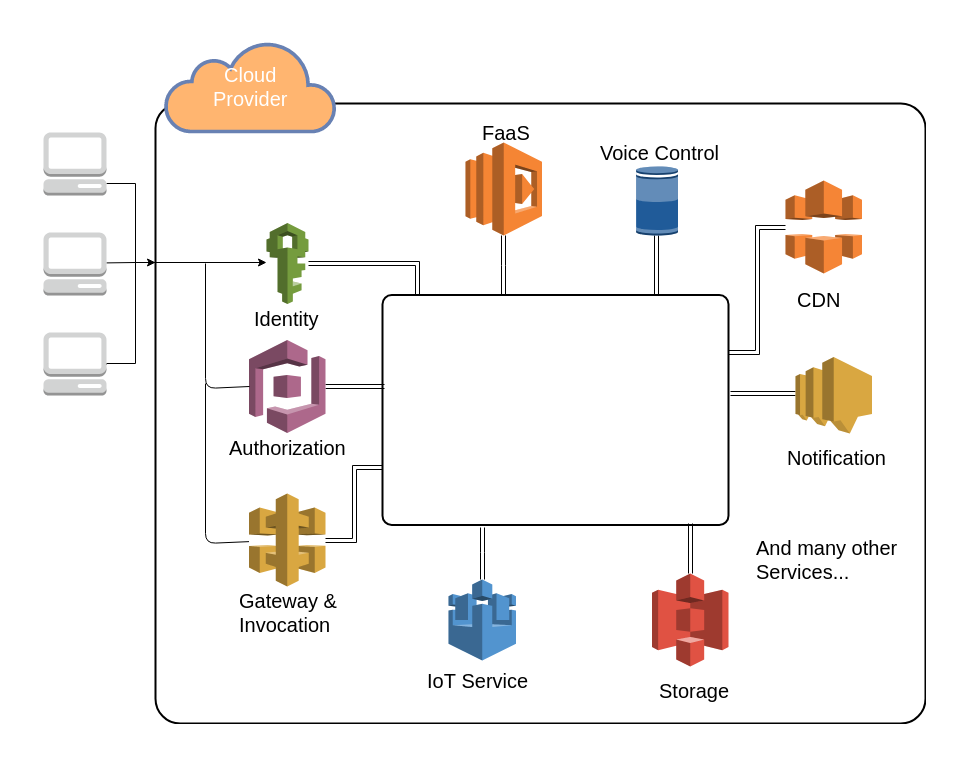
Figure 4 represents some examples of different cloud models from different cloud providers. Next level on cloud service model would be Software as a Service(SaaS) which is a software licensing and delivery model in which software is licensed on a subscription basis and is centrally hosted [7], in another word, the complete cloud based applications that users can use them directly like Google Apps, Dropbox, Salesforce, Cisco WebEx, Concur, GoToMeeting. 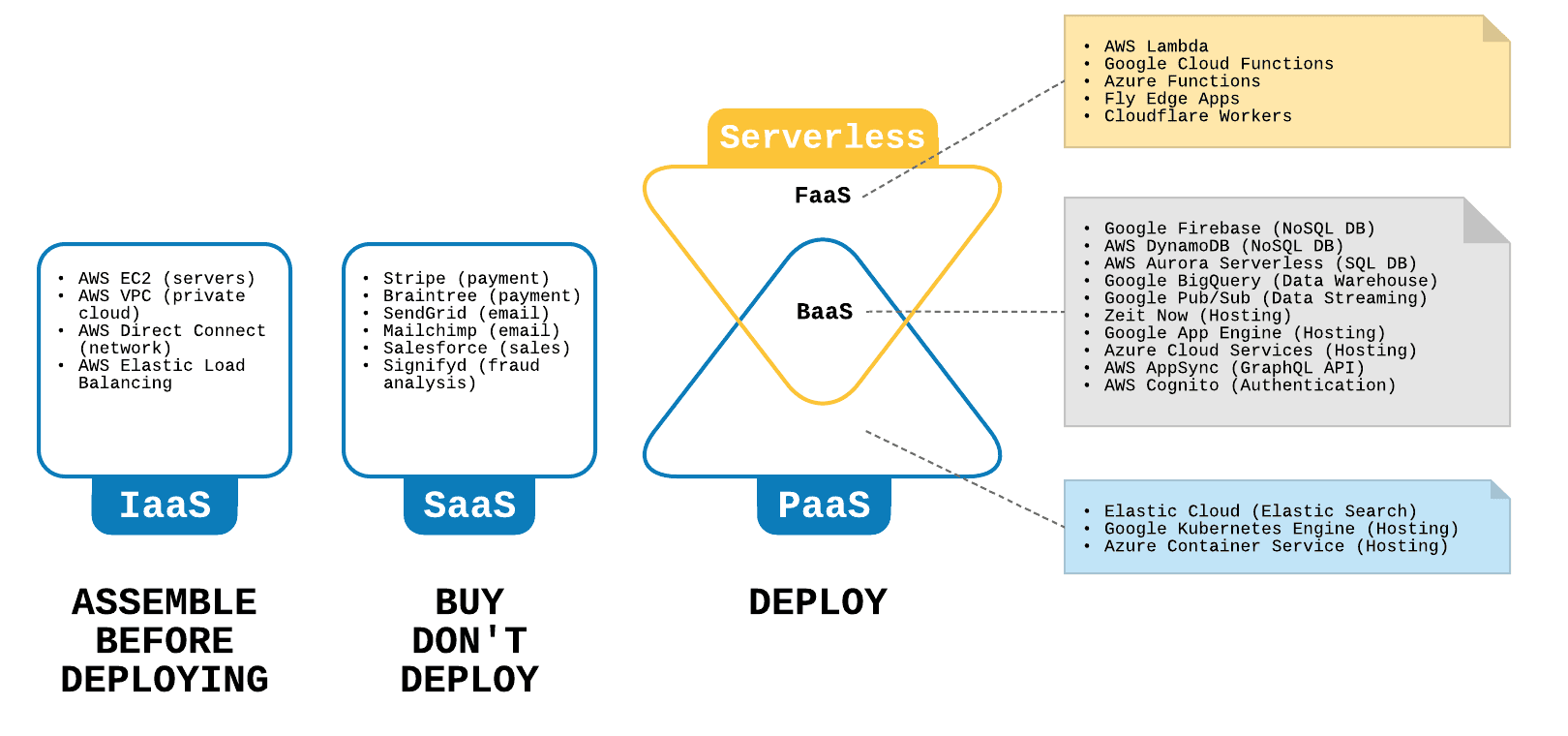
Most famous cloud providers which have serverless platforms ready with FaaS are:
-
AWS and AWS Lambda
-
Microsoft Azure
-
Google Cloud and Google Cloud function
-
IBM Cloud and its Cloud function
-
Oracle with Fnproject
-
Alibaba with Alibaba cloud function
-
Red Hat CloudForms
Applications of serverless computation are varied, and following list shows some of them:
-
Static Website(Amazon S3)
-
Small E-Commerce Platform
-
Chatbot
-
IoT services
-
Big data applications
-
Event-driven systems
-
etc
The functionality of serverless applications in all providers is somehow similar in a way that the client will send a request to the cloud provider, this cause specific event(Handler) to be triggered and consequently, the related function(s) will be fetched. Then the function will be loaded on to the container, and after building the response, finally, the user will receive it. Figure 5 gives insight into the requesting and handling in more detail and Figure 6 gives the general overview of the procedure. Serverless use case, platforms, and toolkits are discussed in the following sections.
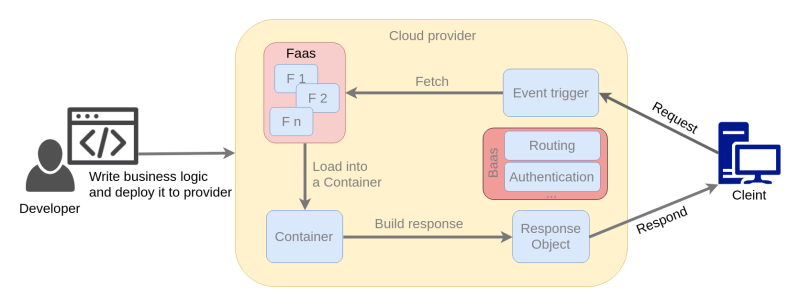
A. Serverless Usecase
I also used the benefits of serverless computation in my project and will describe it shortly. It is an IoT project which uses the following services from AWS:
-
Cognito for authentication and authorization of a user
-
IoT Service
-
S3 and RDS
-
AWS Lambda
-
IoT Analytics
It also consists of three major computations namely Cloud-, Fog- and Edge-computation. Simplified architecture is shown in Figure 7.
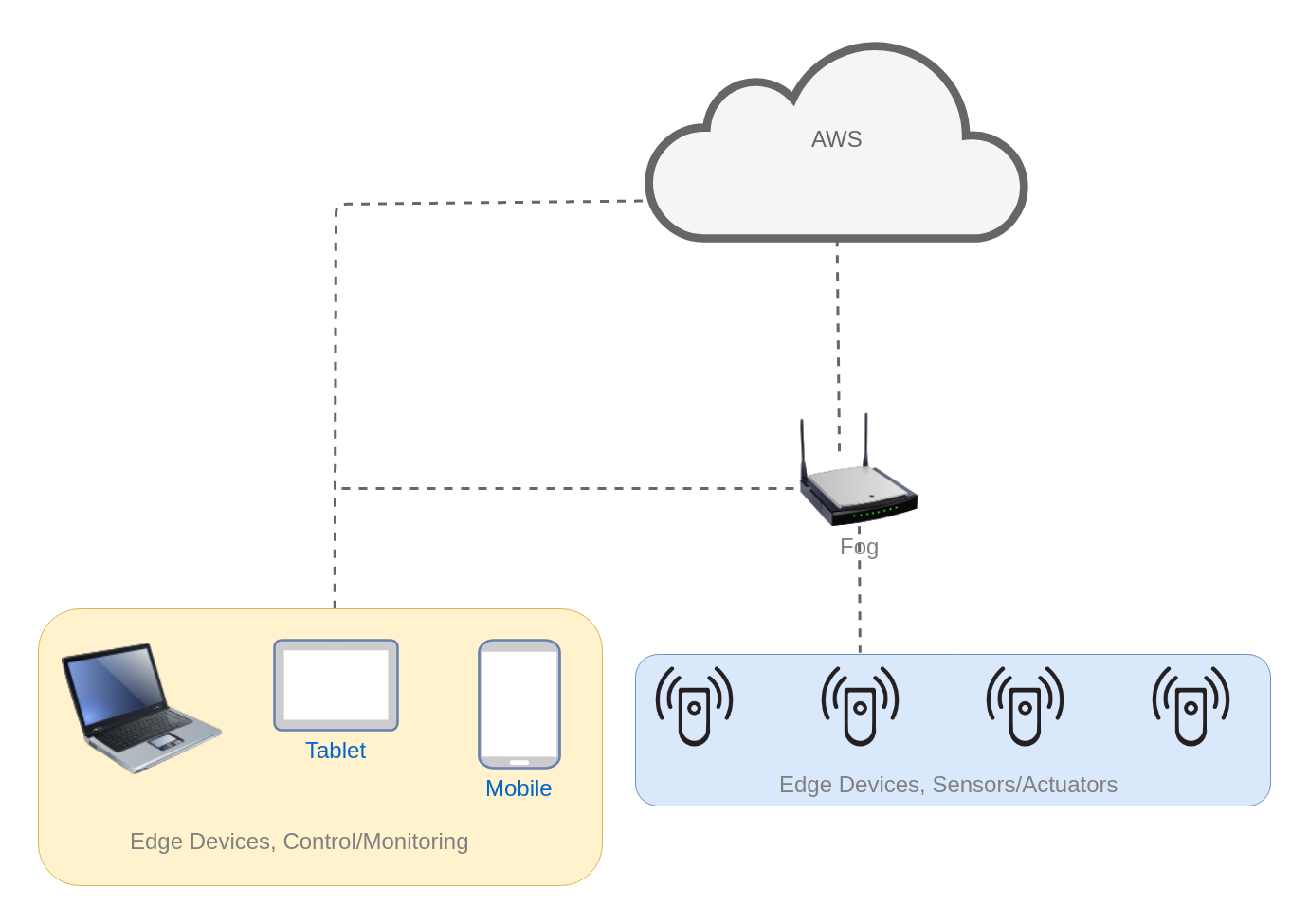
The communication between devices, gateway and cloud are based on secure MQTT. User/App will be defined in AWS Cloud in two ways:
-
as a user, through Cognito for authentication
-
as an IoT device, through Fog for accessing the AWS IoT broker and service.
This architecture can be used for different projects which need some computational power. Edge devices can measure different parameters like temperature, humidity, PH, camera, etc. and send them to upper levels, namely Fog and Cloud, or to other edge devices/mobile app for controlling and monitoring purposes. Some IoT devices which have a camera, need more computational power for doing Machine Learning processes. In order to enable this functionality pictures/frames should be sent to the cloud as there is no limitation for computational power.
The usage of serverless computation in this project will be done by defining several types of Lambdas in AWS which are as follows:
-
For saving values in the database. Each sensor will send data to the cloud at each hour by default. These values will be timestamped and stored on RDS.
-
For requesting another AWS services for the edges. Some edges which have a camera, need to send data to the cloud in order to process and store. So they trigger lambda first to store on database and starting ML processing.
-
Exchanging data between IoT devices. This lambda will be triggered whenever one device wants to send its data to the other device which are not in the same group.
These lambdas can be triggered in two ways with the use of API Gateway or MQTT. I’ve used VS Code for developing lambdas, and deployment has been done directly in AWS console. There are lots of serverless toolkits, for development and deployment of a serverless application, and serverless platforms that we’ll see them in the next sections.
Continue Reading: Serverless Computing – Part II
Security in IoT – Security solution for IoT communication protocol
Security in IoT – Insecure physical layer cause insecure application layer
Security in IoT – Distributed Danial of Service (DDoS) II
About The Author
Tech Enthusiast